

자바 스트림(Stream) API 시작
자바 8에서 추가된 스트림(Stream)은 함수형 프로그래밍에서 단계적으로 정의된 계산을 처리하기 위한 인터페이스입니다. 이전의 자바 I/O에서 나오는 InputStream, OutputStream과는 다른 개념으로, 데이터의 흐름으로 배열 또는 컬렉션 인스턴스에 함수를 조합하여 원하는 결과를 필터링하고 가공된 결과를 손쉽게 처리할 수 있습니다.
스트림은 데이터 소스를 추상화하고 있어 데이터 소스에 상관없이 같은 방식으로 처리할 수 있다는 장점이 있습니다. 또한, 데이터를 다루는데 자주 사용되는 메서드들을 정의해 두고 있어 기존의 방식보다 간결하고 유연한 구현이 가능합니다. 이러한 이유로 스트림은 코딩 테스트 등에 나오는 문제들을 풀 때도 많은 도움이 됩니다.
스트림은 입출력 프로그램에서 말하는 스트림과는 다른 개념이지만, 연속된 데이터의 흐름이라는 관점에서는 비슷합니다. 스트림은 데이터를 처리하는데 있어서 매우 유용한 도구이며, 데이터를 다루는 여러 분야에서 활용됩니다.
스트림을 사용하면 기존의 for문 등을 사용하지 않고도 데이터를 처리할 수 있습니다. 또한, 스트림을 사용하면 병렬 처리가 가능해져 성능 향상에도 도움이 됩니다.
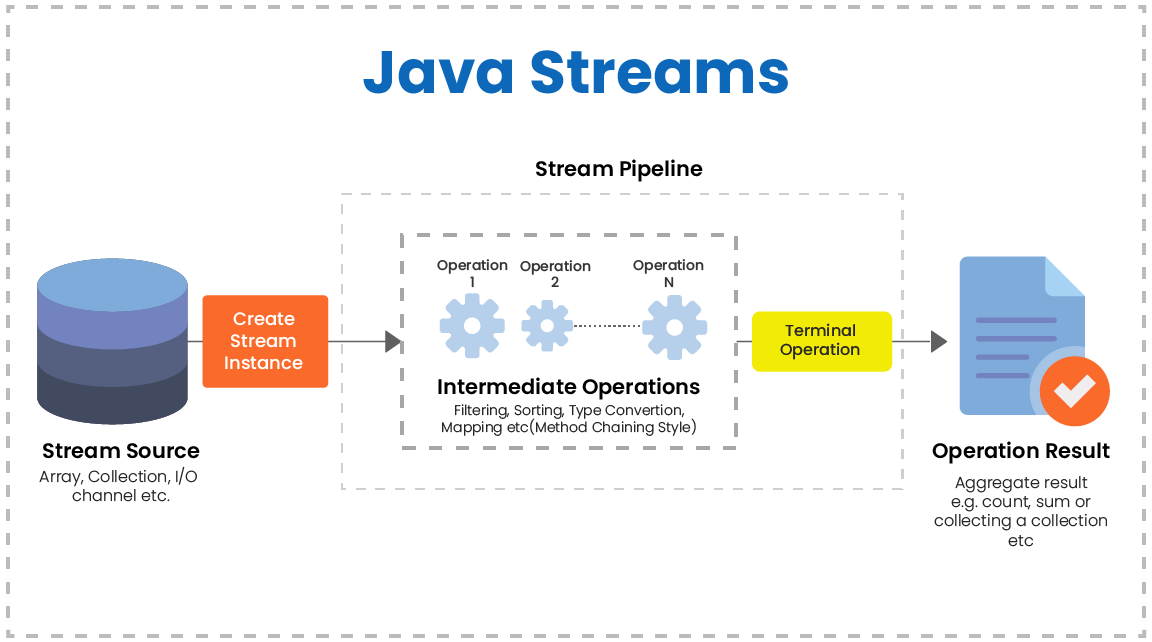
스트림을 사용하기 위해서는 먼저 데이터 소스를 가져와야 합니다. 이 데이터 소스는 배열, 컬렉션, 파일 등 다양한 형태가 될 수 있습니다. 그리고 이러한 데이터 소스에서 스트림을 생성하고, 여러 가지 중간 연산과 최종 연산을 수행하여 원하는 결과를 얻을 수 있습니다.
중간 연산은 스트림을 반환하며 최종 연산은 스트림을 반환하지 않습니다. 중간 연산과 최종 연산을 여러 개 조합하여 하나의 스트림 처리 파이프라인을 만들 수 있습니다.
스트림의 중간 연산에는 filter(), map(), flatMap() 등이 있으며, 최종 연산에는 forEach(), collect(), reduce() 등이 있습니다. 이러한 연산들을 조합하여 다양한 데이터 처리 작업을 수행할 수 있습니다.
스트림은 자바 8부터 추가된 기능으로, 함수형 프로그래밍에서 매우 유용한 도구입니다. 스트림을 사용하면 코드의 가독성이 좋아지고 유연성이 높아지며, 성능 향상에도 도움이 됩니다. 따라서, 스트림에 대한 이해와 활용은 모든 자바 개발자에게 필수적인 요소입니다.
기본 for문과 스트림 for문의 차이점
기존 방식은 Arrays나 Collections의 sort 메서드를 사용하여 데이터를 정렬한 다음 for문을 이용해 결과를 출력하는 방식입니다.
List<Person> list = new ArrayList<>();
list.add(new Person("John", 25));
list.add(new Person("Jane", 30));
list.add(new Person("Tom", 35));
for(Person vo : list) {
System.out.println(vo.getName() + " " + vo.getAge());
}
이 방식은 코드가 간단하고 직관적이어서 많은 개발자들이 사용하고 있습니다.
하지만 이 방식은 추가적인 메모리를 사용하여 속도가 느립니다.
만약 예를 들어, sort같은 메서드를 사용하게 된다면, Arrays나 Collections의 sort 메서드는 내부적으로 퀵소트나 머지소트와 같은 알고리즘을 사용합니다. 이 알고리즘들은 보조 메모리가 필요합니다. 그래서 매우 큰 데이터를 정렬할 때는 메모리 부족 문제가 발생할 수 있습니다.
정렬 알고리즘의 시간 복잡도는 O(n log n)입니다. 따라서 데이터의 크기가 커질수록 정렬하는 데 걸리는 시간이 길어집니다. 또한 Arrays나 Collections의 sort 메서드는 내부적으로 단일 스레드로 동작합니다. 그래서 멀티코어 CPU를 사용하더라도 속도 향상을 기대할 수 없습니다.
물론 Java에서도 정렬 메서드를 고도화 시키는 메서드를 제공하고 있습니다.
이 메서드는 배열을 병렬적으로 정렬합니다
Arrays.parallelSort(strArr);
반면, Stream API는 데이터 처리 속도를 크게 향상시키는데 도움이 됩니다.
멀티코어 CPU를 활용하여 속도가 매우 빠르므로, 대용량 데이터를 다룰 때 특히 자주 이용합니다.
List<Person> list = new ArrayList<>();
list.add(new Person("John", 25));
list.add(new Person("Jane", 30));
list.add(new Person("Tom", 35));
list.stream().forEach(p -> System.out.println(p.getName() + " " + p.getAge()));병렬 정렬 또한 한 문장안에 처리할 수 있습니다.
list.parallelStream().sorted().forEach(System.out::println);컬렉션 프레임워크
컬렉션은 데이터 처리를 위해 각 요소들을 순회하면서 처리해야 하고, 하나의 단계가 끝나고 다른 단계를 진행하는 절차적인 구조를 가지고 있습니다. 이는 복잡한 데이터 처리에서는 효율적이지 않습니다.
이러한 문제점을 해결하기 위해 스트림 API가 도입되었습니다. 스트림은 자료구조를 다루는 방법을 제공하는 것으로, 데이터 소스에 대한 구현체가 아닙니다. 스트림에서 요소들은 저장되지 않고 하부 컬렉션에 보관되거나 필요할 때에만 생성해 사용됩니다. 또한, 스트림 연산은 원본 데이터를 바꾸지 않고 결과를 저장한 새로운 스트림을 반환합니다. 이러한 특징들은 스트림을 이용한 데이터 처리를 효율적으로 만듭니다.
스트림은 가능한 지연(Lazy)처리를 기본으로 합니다. 이는 필요한 시점에만 데이터를 처리한다는 것을 의미합니다. 또한, 스트림은 한번 사용되고 버려집니다. 이는 재활용이 불가능하다는 것을 의미합니다. 로직을 잘못 설계하면 스트림을 반복해서 사용하게 되고, 이는 실행 성능에 문제가 될 수 있습니다.
스트림 API는 람다와 함께 사용하기 좋습니다. 이는 최신의 프로그래밍 언어들과 유사한 방법으로 자바에서도 데이터를 핸들링할 수 있습니다. 또한, 병렬 처리가 컬렉션 내부에서 처리되므로 많은 데이터 처리 시 성능 향상의 효과가 있습니다.
파이썬과 같은 언어는 데이터를 다루는데 최적화된 기능을 제공해 동일한 기능을 자바로 처리하는 것보다 훨씬 간단한 방법으로 처리할 수 있습니다. 그러나 자바에서도 스트림 API를 이용하면 데이터 처리를 효율적으로 할 수 있습니다.
Stream API의 연산 구조
Stream 연산 구조
스트림 연산 구조는 Collections같은 객체 집합.스트림생성().중간연산().최종연산()의 형태로 사용됩니다. 중간연산 메서드는 리턴 타입이 스트림이므로, 계속해서 다른 스트림 메서드를 연결해 사용할 수 있습니다. 최종연산 메서드는 리턴 타입이 스트림이 아닌 것으로, 메서드 체이닝을 끝내는 역할을 합니다.
중간연산들만으로 구성된 메서드 체인은 실행되지 않기 때문에, 최종연산이 실행되어야 중간연산도 처리됩니다. 이러한 특징 때문에, 스트림은 데이터 처리 파이프라인을 구성하는데 매우 유용합니다.
스트림은 다양한 종류의 연산을 제공합니다. 예를 들면, filter(), map(), sorted(), distinct(), limit(), skip() 등이 있습니다. 이러한 연산들은 데이터를 가공하거나 필터링하는 등의 역할을 합니다.
스트림은 병렬 처리를 지원하기 때문에, 대용량 데이터 처리에 매우 유용합니다. 병렬 처리를 위해서는 parallel() 메서드를 사용하면 됩니다.
스트림은 또한 람다식(Lambda Expression)과 함께 사용됩니다. 람다식을 이용하면, 코드의 가독성과 유지보수성을 향상시킬 수 있습니다.
예제를 한번 보겠습니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 7, 8, 9);
List<Integer> result = numbers.stream()
.distinct() // 중복 제거
.limit(7) // 7개로 제한
.sorted() // 정렬
.collect(Collectors.toList()); // 결과를 List로 변환
System.out.println(result);위 코드에서는 먼저 `Arrays.asList()` 메서드를 사용하여 리스트를 생성합니다. 그리고 `stream()` 메서드를 호출하여 스트림을 생성합니다. `distinct()` 메서드를 사용하여 중복 데이터를 제거하고, `limit()` 메서드를 사용하여 데이터를 7개로 제한합니다. 마지막으로 `sorted()` 메서드를 사용하여 정렬한 다음, `collect()` 메서드를 사용하여 결과를 List로 변환합니다.
위 코드를 실행하면 `[1, 2, 3, 4, 5, 6, 7]`가 출력됩니다.
Empty Stream
비어 있는 스트림을 생성하기 위해서는 empty() 메서드를 사용합니다. 아래와 같이 String 타입의 비어있는 스트림을 생성할 수 있습니다.
Stream<String> streamEmpty = Stream.empty();Collection Stream
컬렉션을 이용하여 스트림을 생성할 수도 있습니다.
List<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stream = list.stream();Array Stream
배열을 이용하여 스트림을 생성할 수도 있습니다.
int[] arr = {1, 2, 3, 4, 5};
IntStream intStream = Arrays.stream(arr);String Stream
문자열을 이용하여 스트림을 생성할 수도 있습니다.
String str = "hello world";
Stream<Character> charStream = str.chars().mapToObj(c -> (char) c);File Stream
파일을 이용하여 스트림을 생성할 수도 있습니다.
Path path = Paths.get("file.txt");
Stream<String> fileStream = Files.lines(path);Parallel Stream
아래 코드에서는 parallelStream() 메소드를 호출하여 병렬 스트림을 생성하고, filter() 메소드를 사용하여 짝수만 필터링한 후 forEach() 메소드를 사용하여 출력합니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.parallelStream()
.filter(n -> n % 2 == 0)
.forEach(System.out::println);Stream API 중간 연산 메서드
중간 연산 메서드
중간 연산 메서드는 스트림의 요소들을 가공하거나 걸러내는 등의 역할을 합니다. 이를 통해 스트림의 처리 속도와 효율성을 높일 수 있습니다.
1. filter
filter 메서드는 조건에 맞는 요소들만을 걸러내는 역할을 합니다. 숫자 리스트에서 짝수만을 걸러내는 코드는 다음과 같습니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
2. map
map 메서드는 스트림의 요소를 다른 요소로 변환하는 중간 연산 메서드입니다. map을 사용하면 스트림의 요소를 하나씩 꺼내서 변환한 후 새로운 스트림을 반환합니다. 변환 함수를 인수로 받아서 요소를 변환하므로, 다양한 형태의 데이터를 다룰 수 있습니다.
List<String> words = Arrays.asList("apple", "banana", "orange");
// 문자열 리스트에서 각 문자열의 길이를 구하는 코드
List<Integer> wordLengths = words.stream()
.map(String::length)
.collect(Collectors.toList());
// 문자열 리스트를 대문자로 변환하는 코드
List<String> upperList = words.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
3. flatMap
flatMap 메서드는 스트림의 각 요소에 대해 하나 이상의 스트림을 만든 다음, 모든 스트림을 하나의 스트림으로 연결하는 역할을 합니다. 문자열 리스트에서 각 문자열을 단어로 분리한 후, 모든 단어들을 하나의 리스트로 만드는 코드는 다음과 같습니다.
List<String> lines = Arrays.asList("Hello World", "Java Stream API", "Functional Programming");
List<String> words = lines.stream()
.flatMap(line -> Arrays.stream(line.split(" ")))
.collect(Collectors.toList());
4. distinct
distinct 메서드는 중복된 요소들을 제거하는 역할을 합니다. 숫자 리스트에서 중복된 숫자를 제거하는 코드는 다음과 같습니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 2, 4, 3);
List<Integer> distinctNumbers = numbers.stream()
.distinct()
.collect(Collectors.toList());
5. sorted
sorted 메서드는 요소들을 정렬하는 역할을 합니다. 문자열 리스트를 알파벳순으로 정렬하는 코드는 다음과 같습니다.
List<String> words = Arrays.asList("apple", "banana", "orange");
List<String> sortedWords = words.stream()
.sorted()
.collect(Collectors.toList());
6. peek
peek 메서드는 요소들을 소비하면서 중간 결과를 출력하는 역할을 합니다. 숫자 리스트에서 짝수만 출력하면서 짝수의 개수를 세는 코드는 다음과 같습니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
long count = numbers.stream()
.filter(n -> n % 2 == 0)
.peek(System.out::println)
.count();
System.out.println("Count: " + count);
7. limit
limit 메서드는 스트림에서 처음부터 지정한 개수만큼의 요소를 추출하는 메서드입니다. 이 메서드를 사용하면 스트림의 크기를 제한하고, 효율적인 처리가 가능합니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 아래 코드는 1부터 10까지의 정수 중에서 짝수만을 추출하고,
// 그 중에서 처음 3개의 요소만을 출력하는 코드입니다. 결과는 다음과 같습니다.
// 2
// 4
// 6
numbers.stream()
.filter(n -> n % 2 == 0)
.limit(3)
.forEach(System.out::println);
8. skip
skip 메서드는 스트림에서 처음 N개의 요소를 제외한 나머지 요소들로 구성된 새로운 스트림을 반환합니다.
skip 메서드는 대용량 데이터를 다룰 때 유용하게 사용됩니다. 예를 들어, 수백만 개의 데이터가 포함된 데이터베이스 테이블에서 처음 몇 개의 레코드를 건너뛰고 나머지 레코드들만 처리해야 할 경우 skip 메서드를 사용할 수 있습니다.
하지만 skip 메서드는 일부 상황에서 성능 문제가 발생할 수 있습니다. 스킵할 요소의 개수가 많은 경우에는 모든 요소를 순회하면서 스킵해야 하기 때문입니다.
Stream<T> skip(long n)
// 여기서 n은 스킵할 요소의 개수를 의미합니다.
// skip 메서드는 스트림의 처음 n개의 요소를 제외한 나머지 요소들로 구성된 스트림을 반환합니다.
String[] fruits = {"apple", "banana", "orange", "kiwi", "grape"};
// 이 배열을 스트림으로 변환하고, 처음 2개의 요소를 제외한
// 나머지 요소들로 구성된 스트림을 반환하려면 다음과 같이 skip 메서드를 사용할 수 있습니다.
Stream<String> fruitStream = Arrays.stream(fruits);
Stream<String> newFruitStream = fruitStream.skip(2);
// 위 코드에서 newFruitStream은
// "orange", "kiwi", "grape" 요소들로 구성된 새로운 스트림이 됩니다.
최종 연산 메서드
최종 연산 메서드는 Stream API를 이용한 데이터 처리 결과를 반환하며, 스트림 파이프라인을 종료시키는 역할을 합니다.
1. forEach()
forEach() 메서드는 스트림의 각 요소에 대해 지정된 작업을 수행합니다. 이 메서드는 void를 반환하며, 스트림 파이프라인을 종료시킵니다. 아래 코드는 스트림의 각 요소를 출력합니다.
List<String> list = Arrays.asList("Java", "Python", "C++");
list.stream().forEach(System.out::println);
2. count()
count() 메서드는 스트림의 요소 수를 반환합니다. 이 메서드는 long을 반환하며, 스트림 파이프라인을 종료시킵니다. 예를 들어, 아래 코드는 스트림의 요소 수를 출력합니다.
List<String> list = Arrays.asList("Java", "Python", "C++");
long count = list.stream().count();
System.out.println("Count: " + count);
3. collect()
collect() 메서드는 스트림의 요소를 수집하여 컬렉션으로 반환합니다. 이 메서드는 Collectors 클래스의 정적 메서드를 이용하여 수집 방식을 지정할 수 있습니다. 아래 코드는 스트림의 요소를 List로 수집합니다.
List<String> list = Arrays.asList("Java", "Python", "C++");
List<String> collectedList = list.stream().collect(Collectors.toList());
4. reduce()
reduce() 메서드는 스트림의 요소를 하나의 값으로 줄입니다. 이 메서드는 BinaryOperator<T> 인터페이스를 구현하는 람다식을 이용하여 연산 방식을 지정할 수 있습니다. 아래 코드는 스트림의 요소를 모두 더한 값을 반환합니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
5. anyMatch(), allMatch(), noneMatch()
anyMatch(), allMatch(), noneMatch() 메서드는 각각 스트림의 요소 중 하나라도 조건에 맞으면 true, 모두 조건에 맞으면 true, 모두 조건에 맞지 않으면 true를 반환합니다. 이 메서드들은 Predicate<T> 인터페이스를 구현하는 람다식을 이용하여 조건을 지정할 수 있습니다. 아래 코드는 스트림의 요소 중 3의 배수가 하나라도 있는지 검사합니다.
// anyMatch()
// anyMatch() 메서드는 스트림에 속한 요소 중 하나 이상이 주어진 조건을 만족하는지 검사합니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
boolean isAnyMatch = numbers.stream()
.anyMatch(n -> n % 2 == 0);
// isAnyMatch == true
// allMatch()
// allMatch() 메서드는 스트림에 속한 모든 요소가 주어진 조건을 만족하는지 검사합니다.
List<Integer> numbers = Arrays.asList(2, 4, 6, 8, 10);
boolean isAllMatch = numbers.stream()
.allMatch(n -> n % 2 == 0);
// isAllMatch == true
// noneMatch()
// noneMatch() 메서드는 스트림에 속한 모든 요소가 주어진 조건을 만족하지 않는지 검사합니다.
List<Integer> numbers = Arrays.asList(1, 3, 5, 7, 9);
boolean isNoneMatch = numbers.stream()
.noneMatch(n -> n % 2 == 0);
// isNoneMatch == true
6. findAny(), findFirst()
findAny(), findFirst() 메서드는 스트림의 요소 중 하나를 반환합니다. findAny() 메서드는 병렬 처리 시 성능이 더 좋으며, findFirst() 메서드는 첫 번째 요소를 반환합니다. 아래 코드는 스트림의 첫 번째 요소를 반환합니다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// findFirst() 메서드는 스트림의 첫 번째 요소를 반환합니다.
// 이 때, 스트림이 비어있을 경우 빈 Optional 객체를 반환합니다.
// 이 메서드는 병렬 스트림에서는 첫 번째 요소를 반환하는 것이 보장되지 않으므로 주의해야 합니다.
Optional<Integer> result = numbers.stream().findFirst();
if(result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("해당 요소가 존재하지 않습니다.");
}
// findAny() 메서드는 스트림에서 임의의 요소를 반환합니다.
// 이 때, 병렬 스트림에서는 가장 먼저 발견된 요소를 반환하기 때문에,
// 병렬 스트림에서는 findFirst()보다 더 효율적으로 동작할 수 있습니다.
Optional<Integer> result = numbers.stream()
.filter(n -> n % 2 == 0)
.findAny();
if (result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("No result found");
}
// 이 두 메서드 모두 Optional 타입을 반환하기 때문에,
// 요소가 존재하지 않을 경우에 대한 예외 처리를 해주어야 합니다.
7. min(), max()
min() 메서드는 스트림에서 가장 작은 값을 반환합니다. 이 때, 스트림의 요소는 Comparable 인터페이스를 구현해야 합니다.
max() 메서드는 min() 메서드와 반대로 스트림에서 가장 큰 값을 반환합니다. 마찬가지로, 스트림의 요소는 Comparable 인터페이스를 구현해야 합니다.
List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3);
// min()
Optional<Integer> min = numbers.stream().min(Integer::compare); // 1
// max()
Optional<Integer> max = numbers.stream().max(Integer::compare); // 9
8. sum(), average()
sum() 메서드는 스트림의 모든 요소를 합산한 결과를 반환합니다. 이 메서드는 오직 숫자 타입에 대해서만 사용할 수 있으며, IntStream, LongStream, DoubleStream 인터페이스에서 사용할 수 있습니다.
average() 메서드는 스트림의 모든 요소의 평균값을 반환합니다. sum()과 마찬가지로 숫자 타입에 대해서만 사용할 수 있으며, IntStream, LongStream, DoubleStream 인터페이스에서 사용할 수 있습니다.
// sum()
int sum = IntStream.of(1, 2, 3, 4, 5)
.sum();
System.out.println(sum); // 15
// average()
double average = DoubleStream.of(1.5, 2.5, 3.5)
.average()
.orElse(Double.NaN);
System.out.println(average); // 2.5마무리
정리도 할겸 공부도 할겸, 많은 곳에서 참고하면서 작성 해봤는데요 여러분들도 한번 씩 더 공부하시면 좋을 것 같아서 정리해서 올립니다!
'프로그래밍 언어 > JAVA' 카테고리의 다른 글
| 자바의 인터페이스(Interface)에 대해서 알아보자 (0) | 2023.06.21 |
|---|---|
| 자바(JAVA)란 무엇이며 필요성과 중요성을 알아보자 (0) | 2023.06.15 |